This piece is the first in our series on pedagogy, focused on themes of inclusivity and equity. The introduction to the series can be read here and pieces in the series will be linked in the introduction as we publish them.
I met for coffee with a friend, a retired English faculty colleague, a few years ago and after catching up on current events, we got onto the subject of our teaching methods. She had taught at my campus for 36 years, and I occupied her previous office. I described a few of my approaches to inclusive pedagogy and expressed my interest in cutting edge theories of teaching and learning. As we compared notes, I realized that my colleague had utilized many of my “cutting edge” approaches in the 1970s. “Yes, we tried that,” she thoughtfully said. I had mentioned my interest in encouraging students to write without self-criticism toward their “home” language or dialect, the natural way we all speak (and text). Writing is recursive. We can always seek feedback, self-edit, review, and revise.
A May 9, 1971 article in the St. Louis Post-Dispatch explains the concept of the Open Door to Higher Education.
At first, I was discomfited as I mulled that my cutting edge method existed 45 years earlier, but then it occurred to me that my colleague was a trailblazer. I had inherited her and her colleagues’inclusive, institutional framework. The ongoing conversation about inclusive pedagogy at my college was initiated by them. She had been at the forefront of one of the most transformational moments in education: The creation of the community college.
Neue Helvetica Arabic (sample text), designed by Nadine Chahine
If you were becoming an Arabic type designer, one of the things you would need to consider, oddly enough, is Latin type design: much Arabic type design involves creating Arabic counterparts to existing Latin typefaces, a process known as typographic matchmaking. The Arabic script was incorporated into printing technology –outside of Arabophone contexts for the purposes of those who studied Islam for both academic and polemic purposes– roughly a century after the Latin script: Gutenberg, the inventor of Latin movable type, didn’t design printing with the Arabic script in mind. Arabic is composed of 28 letters, which have four letterforms (isolated, initial, medial and final forms), thus requiring a large number of type pieces to be created and the process was time-consuming. Today, while the computer allows us to communicate in Arabic without having to worry about the multiple letterforms, out of the same Gutenbergian legacy comes typographic matchmaking.
In typographic matchmaking, a type designer studies the letterforms of the Latin typeface they are interested in and incorporates their features into the design of Arabic letterforms while maintaining their physical appearance as Arabic letters. An example is Neue Helvetica Arabic, based on the Latin script typeface Neue Helvetica. Typographic matchmaking represents a cultural and practical discourse that Arabic type designers engage in as they work with Arabic type: consequently, Arabic speakers have few typefaces that they can rely on for day-to-day uses.
Ever since podcasting hit the scene in the early 2000s, there has been no shortage of content on the Middle East, North Africa, the Islamicate world, and on Muslims. We’ve assembled a list here –subject to eventual updates and suggestions– of podcasts on history, current events, and culture from the Middle East, North Africa, the Balkans and the Islamic(ate) world more generally. We have also included a few other podcasts on Muslim cultural and intellectual matters. This list is by no means exhaustive and we look forward to developing it more: you can DM us suggestions on Twitter or Facebook and you can email us or comment below.
For those of you who are uninitiated in the ways of podcasts, a basic guide: you can either listen to them streamed from their sites on your computer or tablet or you can download a podcast catcher app (iPhones come preloaded with the Podcast app). Many are uploaded to Soundcloud (which is both a website and an app). Other podcast apps include Overcast, Stitcher, Anchor, Breaker, PodTail, Google Podcasts and Spotify. Once you’ve installed the apps, search by podcast title (or episode title) to find what you’re looking for. You can choose to subscribe or just listen to individual episodes (either via downloads or streaming) If you are having problems finding the podcasts on your podcast catcher of choice, please visit the podcast’s homepage to see if it is only available on certain platforms.
I have hesitated to write this piece because, as I told the person who commissioned it, everything about the archive(s), archivists, and their tepid relationship with historians and humanities folk has already been said in academic articles, books, conferences, and in less diplomatic ways on social media. Perhaps the most succinct and well-presented perspective of archivy’s relationship with other academics is Caswell’s (2016) article, “ ’The Archive’ Is Not an Archives: On Acknowledging the Intellectual Contributions of Archival Studies.” I would not be offended if you stopped reading this right here and just clicked on the link to that article now.
Caswell (2016) acknowledges in her article previous work on the topic by Lingel (2013), “This is not an archive” , who spoke about the limits of the archives as a metaphor especially when the theories are constructed “in ignorance of archival work.” Recently, Gibbons (2020) has written “Derrida in the Archival Multiverse” which begins with the important point all of our voices have grown hoarse repeating, “Archival theory did not start (nor end) with Derrida.” As Eastwood (2017) explained, archivists themselves “have long engaged in characterizing the nature of archives.”
We recently tweeted out some of our favorite blogs to follow: we threw out a couple of names you probably know and some you might not have had the chance to follow. Then our followers (and some of the people we tagged) tweeted back at us some of their favorites (particular shout-outs to Rich Heffron, Hind Makki and M Lynx Qualey). Here it is, in list form, if you don’t follow us on Twitter. Please either comment bellow on your favorites, tweet at us, or email us at hazineblog@gmail.com and we’ll update the list as we go along!
How you can use Sezgin’s GAS to improve your German, learn about your field, and find Arabic manuscripts.
So you want to learn German. Or more
likely, you are required to learn
German for your degree in Near Eastern Studies, Middle Eastern History, or
Islamic Studies. If your graduate program is like mine, you might not receive
course credit for taking German courses so you are largely left to acquire
reading comprehension on your own. For those of you in this situation, I have
put together a strategy for gaining German reading competency that is targeted
for students in our field, especially for those focused on early and medieval
Islamic history and thought. This strategy is hardly foolproof; rather, it is
the result of the numerous mistakes I have made while studying German in graduate
school…mistakes that I hope you can benefit from.
There is a long-standing joke in Near
Eastern Studies that “German is the most important Semitic language” due to the
numerous field-defining contributions of scholars writing in German (h/t to
@shahanshah). While many of these works have been translated into English or
French or Arabic, an abundance of German scholarly literature in Near Eastern
Studies, especially articles, exists only in die Muttersprache. Speaking from experience, there’s a good chance
that just when you think you have accounted for the significant secondary
literature concerning your dissertation topic, you will stumble upon an
exhaustively researched tome in German on your topic that you cannot afford to
ignore. And if you do ignore it, you can count on one of your dissertation
committee members to reference it during your proposal. But enough with the
fear mongering.
•••
If you want, or need, to gain reading competency in German, an effective and edifying way to go about it is by utilizing Fuat Sezgin’s Geschichte des Arabischen Schrifttums (GAS), an invaluable bio-bibliographical survey of Arabic literature up to the mid-fifth/- eleventh century. Why Sezgin’s GAS and not Carl Brockelmann’s Geschichte der arabischen Litteratur (GAL)? Well, Sezgin’s survey is both more current and comprehensive for classical Arabic literature, and it is much less cumbersome to use than Brockelmann. Heck, the Middle East Librarians Association published a guide to Brockelmann’s GALin 1974 because the work’s organization and constant abbreviations were so obtuse to the uninitiated. If your research is focused on the post- classical period (i.e. after 360/1050), however, you may want to use Brockelmann’s GAL rather than Sezgin’s GAS for the proposed learning method below. In 2016, Brill published an English translation of Brockelmann’s GAL, which is useful but it won’t improve your German.
Begin by getting your hands on the
volume of Sezgin’s GAS that is most
applicable to your area of focus. For instance, if your research focuses on
hadith then check out Volume 1, which covers the fields of Quranic Studies,
hadith, history, jurisprudence, theology (dogma), and mysticism. Brill
published the first nine volumes of GAS while
the rest, volumes ten through seventeen, are available from the Institut für
Geschichte der Arabisch-Islamischen Wissenschaften.
Once you have acquired the appropriate GAS volume, grab your preferred
dictionary and reading grammar and go to the section that concerns your area of
focus. As for reading grammars in English, I recommend either April Wilson’s German Quickly or Karl Sandberg and John
Wendel’s German for Reading, both of which are commonly
used by instructors teaching German reading comprehension. I am partial to
April Wilson’s grammar as it is the product of her decades of experience
preparing University of Chicago graduate students for the German reading exam.
With your dictionary and grammar
handy but closed—for the time being—begin reading through Sezgin’s
chronologically-arranged biographies of the scholars who composed works in
Arabic, both extant and lost, in your field of study. For now, just focus on reading
Sezgin’s biographies, ignoring his bibliographical notes below the biographical
entry. The biographies will provide you with fundamental information about the
author’s life as well as the prime vocabulary necessary to read academic
literature in Islamic Studies. For example, here is the biography (outlined in
red) of Nāfiʿ b. Nuʿaym, the famous second-/eighth-century Medinan Quran
reciter, who provided the impetus for this post.
When reading through the biographies,
like the one above, write down the words— especially the verbs—that you are not
familiar with. If absolutely necessary
to obtain an inkling of comprehension, look up the definitions of select words
while reading. But try your hardest to avoid looking up definitions at this
point. Instead try to infer the meaning of unknown words from the context, an
invaluable skill for gaining reading comprehension in a foreign language.
Inferring the meaning of words may be easier than you think since the
biographies concern individuals in your area of expertise. And you’ll get
better at it with practice.
** Brief aside: You will notice that
Sezgin regularly uses abbreviations, especially for names, which he derives
from Brockelmann. You can find the key for Sezgin’s abbreviation system at the
beginning of each volume, pictured below. Sezgin also regularly provides the
citation for Brockelmann’s GAL entry.
For example, see the beginning of Nāfiʿ’s biography above where we find: von Br. S I, 328 = “from Brockelmann,
Supplement 1, page 328. Don’t worry, you will quickly become familiar with the
abbreviations, some of which are just basic German abbreviations—e.g. “s.” = siehe / see; “S.” = Seite / page; “Jh.” = Jahrhundert
/ century; “vgl.” = vergleiche /
compare; “eb.” = ebenda / ibidem. **
After you’ve read through a handful
of biographies, look up the definitions for the list of unknown words that you
wrote down and make vocab cards for each word or phrase. I still prefer
handwritten vocab cards as the act of writing aids my memorization of definitions—and there’s evidence for
this. Nevertheless, handwritten vocab cards can be inconvenient, so you may
prefer to use a digital app such as Anki or iFlash, both of
which I’ve enjoyed using for studying vocab on the go. Whether you are using
handwritten cards or an app, the key to vocab acquisition is to review your
Sezgin cards on a daily basis. Look
at the L1, your native or stronger language, side of the card first and attempt to recall the German
word from memory.
If you opt for handwritten vocab
cards, I recommend this system: the day after you begin making German vocab
cards from reading Sezgin’s GAS,
review your cards. The ones you get right move to a second pile; the ones you
get wrong or can’t remember stay in the original pile. Each day review your
German vocab, moving the cards you remember correctly one pile to the right and
the ones you don’t one pile to the left. I employ a five-pile system—an honest
week’s work if you remember them correctly every day—and when I remember the
words in the fifth pile correctly they get put in the “memorized box,” which
contains vocab cards that I now know well, but still review on a monthly basis.
My box of Arabic vocab cards from studying in Sana’a in 2007.
So what does this have to do with Sezgin’s GAS? Well, Sezgin’s biographies of
scholars abound with German vocabulary that is particularly relevant for the
study of Arab-Islamic history and thought. His biographies also tend to be
concise, his syntax is quite simple, and his sentences are short. For all these
reasons, Sezgin’s GAS is excellent
for practicing your German and learning field-specific vocabulary while also
learning about the bio-bibliographic history of your specific research area.
You can, and should,
also practice your grammar when reading Sezgin’s biographies. An effective way
to do this is by applying the lessons from your chosen German grammar book to
your reading. For instance, if you just completed a lesson on German pronouns
and their declensions, then apply this lesson by identifying all the pronouns
and their respective cases (i.e. nominative, accusative, genitive, and dative)
in a few biographies. Or break down sentences into their component parts,
identifying the verbs, adverbs, adjectives, nouns, and prepositions while
noting verb tenses, gender, number, cases, and case endings.
If you are required to take a German reading exam, begin attempting to translate Sezgin’s biographies. When you are struggling with your translation, look at other biographies of the scholar from the Encyclopaedia of Islam or Encyclopedia Iranica or Wikipedia to look for clues on what Sezgin might be saying. And don’t get too hung up on translating the exact meaning of the biography at this point, instead shoot for the general meaning (al-riwāya bi-l-maʿnā) rather than a word-for-word translation (al-riwāya bi-l-lafẓ). There is also an Arabic translation of Sezgin’s GAS, which you can use to check your translations.
After you have read through Sezgin’s
biographies in your area of focus, move on to reading his introduction to that
section. This will be much more difficult than reading his short biographies,
but you should now be familiar with the major figures in your respective field
and with the pertinent vocabulary and terminology.
•••
Now comes the fun part: Diving into
Sezgin’s bibliographical notes that are under every biography. My fellow
graduate students, there are thousands, nay tens of thousands, of potential
dissertation topics buried in these bibliographical notes.
For an example of how Sezgin structures his
bio-bibliographical entries, let’s return to Nāfiʿ b. Abī Nuʿaym’s biography. From Sezgin’s biography we
learn the citation for Brockelmann’s entry on Nāfiʿ, Nāfiʿ’s name, and select
details about his life: Nāfiʿ was one of the seven canonical Quran readers, he
grew up in Medina, he supposedly learned Quranic recitation from seventy
Successors yet he wasn’t considered reliable (in hadith transmission), among
his prominent students were al-Aṣmāʿī and Qālūn, and he died in 169/785.
Underneath the biography, Sezgin provides
a list of secondary-source studies that discuss the biographee (I’ve outlined
them in blue). Many of these studies are in German, so you can keep practicing
with more difficult texts. Sezgin’s lists are obviously outdated—the first
volume of GAS was published in
1967—yet many of the studies that he references still hold water. Typically
Sezgin provides a list of the extant medieval Arabic biographies of the scholar
along with more recent biographies (outlined here in orange) directly after his
short biographical entry; however, in the case of Nāfiʿ he switches the order.
Sezgin’s list of biographies for each scholar tends to be relatively
comprehensive and is an informative roadmap for further research into the
respective scholar’s background.
Next Sezgin provides a list of
manuscripts written by, or
attributed to, the scholar. As you’ll see below in the case of Nāfiʿ b. Abī
Nuʿaym, Sezgin mentions works reportedly written by the scholar that are no
longer extant. First, in green, we find the second part of Nāfiʿ’s treatise on
the proper reading of the Quran, al-Qirāʾa,
which is a fifteen-folio manuscript written down in the sixth/twelfth century
and housed at the Ẓāhiriyya Library in Damascus. (Photocopies of the Ẓāhiriyya
Library’s collection of majmuʿāt manuscripts
can be found online here,
and here is the link to Nāfiʿ’s
al-Qirāʾa manuscript,
which is located at the end of the majmuʿa.)
The second work (outlined in magenta)
that Sezgin references is a fragment from Nāfiʿ’s Tafsīr, which is once again located among the majmuʿāt at the Ẓāhiriyya library. The final work is a hadith collection of Nāfiʿ
(outlined in yellow). Sezgin first notes that al- Dhahabī referenced
a nuskha of Nāfiʿ’s hadith transmitted by ʿAlī b. ʿAdī b. al-Qaṭṭān (d. 365/976) in the fourth/tenth century, which is no longer extant, before
going on to cite two extant manuscripts of Ibn al-Muqrīʾ al-Isfahānī (d.
381/991), preserved in Cairo and Damascus, that contain a selection of Nāfiʿ’s musnad hadith collection. The Cairo MS
of Ibn al-Muqrīʾ’s work was edited and published in 1991, a PDF of which can be
found here.
When applicable, Sezgin notes the edited editions of works, however, since the publication of the
early volumes of GAS an incredible
amount of manuscripts have been edited and published so it is always good to
check whether a previously unedited MS has been published. The easiest way to
do this is by doing a search on WorldCat and
there’s a chance the published edition of the text may be available online at Waqfeya.
And just like that you’ve gone from
working on your German reading comprehension using Fuat Sezgin’s GAS to finding unpublished manuscripts
that may be central to your next research project. If you don’t have much
experience working with Arabic manuscripts, I urge you not to be intimidated.
For years I put off engaging with the expansive corpus of Arabic manuscripts
because I thought that I needed formal instruction in codicology. Don’t make
the same mistake as me![1][AH2]
•••
So to recap, if you are a student of
Islamic history and thought who needs, or wants, to learn German, Fuat Sezgin’s
Geschichte des Arabischen Schrifttums is
a fantastic source for improving
your reading comprehension because it uses vocabulary pertinent to the field,
his syntax and prose is simple, and his sentences are short. By reading
Sezgin’s GAS you will also get an
overview of the first four-hundred years of scholarly history in your area of
focus while learning about loads of unedited Arabic manuscripts that are
begging for your attention. You may even alight upon your dissertation topic or
next research project. And, frankly, we need more scholars to work on the
Islamic manuscript tradition, so learn enough German to utilize Sezgin and
throw yourself into the vast world of Arabic manuscripts.
•••
Rich Heffron (@richheffron) is a Ph.D. candidate in Islamic history at the University of Chicago and a lecturer in the Department of Philosophy and Religion at Ithaca College. His research focuses on the history of the Muslim scholarly community in early Islamic Syria.
[1] A good way to begin working with Arabic manuscripts is to find an entry in Sezgin’s GAS of a scholar who is of particular interest to you. Go to Sezgin’s bibliographical notes for the scholar and see if any of the manuscripts attributed to them are available online (e.g. the majmuʿāt collection of Ẓāhiriyya) and have been edited and published. Once you’ve gotten your hands on the manuscript and the published edition based off the respective manuscript, start reading through the manuscript and transcribing the portions you can make out. Then check your transcription of the manuscript against the published edition while noting the different editing decisions the editor has made. Read through a few folios a week in this fashion and you’ll quickly get accustomed to the scribe’s hand and you will be able to decipher more and more of the manuscript with less and less effort. If you want a broad introduction to the world of Islamic manuscripts, I highly recommend Evyn Kropf’s (@eckropf) meticulous and up-to-date research guide.
Digitization is changing historical research, and few digitization projects have done more to revolutionize the way we write history than Google Books. This project, in partnership with a number of libraries, has rendered once rare and difficult-to-access printed books increasingly ubiquitous commodities available for download through Google and partner sites such as Hathitrust. This has multiplied the value of rare books that once slumbered in the obscurity of research libraries. Now they can be searched and consulted with unprecedented speed and used to form corpora of historical, cultural, and linguistic material. The change is not simply about accessing more data; it is about new ways of organizing and interpreting that data afforded by its new digital form. The Google Books Ngram Viewer is one important example of how digitization can transform the types of research questions asked and answered in the social sciences and the humanities. It features a simple web interface to Google’s rich database of scanned texts from centuries of publishing in English, as well as other languages, such as French, German, Spanish, Italian, Russian, Hebrew, and Chinese.
For researchers enticed by this description but unsure what an n-gram is or how to use it, we offer this brief introduction. An n-gram is simply an instance of a word or phrase within a corpus, where n is a variable representing the number of words. Google’s service allows researchers to track the relative frequency of n-grams over time and generates plots (called T-transformations) to illustrate and contrast the usage of words and phrases over years. While the causal link between language use and the statistical patterns found in published materials is not necessarily linear, Ngram can offer a window into shifts in human language and society by substantiating putative trends formerly described only qualitatively and offering new questions and potential areas of inquiry, particularly when interpreted within an informed historical context.
Ngram has yet to make a big splash among academic historians, who are perhaps less accustomed to using and evaluating statistical data than linguists. However, given that Ngram draws on the very sources used by historians and has the power to represent information about them in a diachronic manner, we believe that it has much to offer researchers. Moreover, the visualization of this data presents in supremely legible form a representation of important historical points that make Ngram ideal for classroom and conference presentations.
Yet, at the same time, just as digitization has created the potential for “cherry-picking” data from searchable texts without proper care for context, Google Ngram has the power to mislead scholars that ask the wrong questions. In order to elaborate further on the benefits and hazards of the Google Ngram viewers, we will start with a basic “historian’s example” of how Ngram can be used and follow with an example from linguistics that demonstrates how to make the most of Ngram searches.
A Historian’s Example
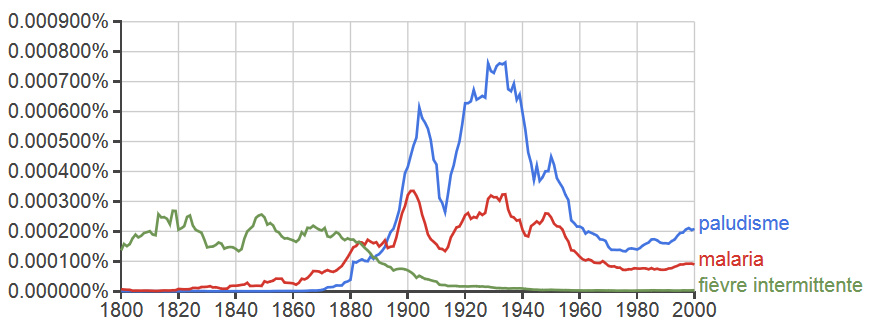
When writing the history of disease, it is relatively easy to formulate a narrative based on dates marking certain influential medical discoveries. For example, in the case of malaria, we know that Charles Laveran identified the parasite that causes malaria in 1880 and Ronald Ross first identified the parasite within the mosquito in 1897, which subsequently led to the discovery that mosquitos transmit malaria between humans. Yet, this tells us little about how understandings of disease changed over time, and how former notions regarding disease persisted alongside new ones.
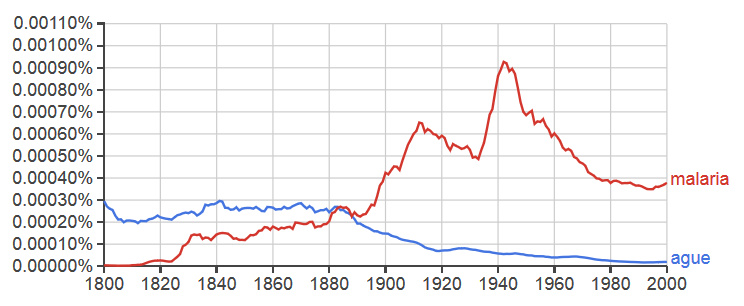
One of the challenging questions faced by disease historians is thus how to represent changing understandings of disease quantitatively rather than with anecdotal evidence. Google Ngram offers one possible avenue. Malaria is a relatively new term in the English language that nonetheless predates the aforementioned discoveries. Its etymology is rooted in medeival Italian mal aria (bad air) and refers to the idea that the disease was caused by dirty emanations from swamps and rotting organic matter. However, the term malaria became the standard way of referring to the disease only after the discovery of the parasite. Before this, there were various ways of referring to the unique symptoms of recurring fever and chills associated with malaria.
The above n-gram diachronically charts the relative prevalence of two words roughly referring to the same illness in the English language. The first, ague (a-gyu), is now an exceedingly rare term that few English speakers would recognize today. Variations of this word were once common in a number of European languages. It comes from the Latin term for “acute fevers (febris acuta)”, the most glaring symptom of malaria. The second, is the word malaria universally applied today in reference to that illness in English. The graph shows the respective fates of the two terms over the centuries. The term malaria began to spread during the early nineteenth century and rose in importance, we presume, due in part to medical research and writings on its causes and effects. The two terms were of nearly identical importance in 1880 when Laveran first discovered the parasite. Following this discovery, we see a rise in the occurrences of malaria in written English (Laveran in fact used paludisme which became “paludism” in English). Use of the word malaria peaked around the World War II era, when malaria was a major killer among Allied military personnel in the Pacific theater and research into the use of DDT in combating the illness was at its height. Meanwhile, ague continued to wane as the cause and symptom of malaria were merged. However, its use lingered in the intervening decades, representing the remnants of past understandings of disease. This n-gram shows a similar trend in the medical vocabulary of the French language, indicating an epilinguistic phenomenon regarding understandings of disease.
In the above case, we have used n-gram to represent graphically a trend that was already vaguely understood but hard to visualize in a quantitative manner. The n-gram does not necessarily make the discovery on its own, but it certainly helps us to strengthen our claims. We can also use Google Ngram Viewer to stimulate new questions. For example, we might ask how the rise of medical science has led to a shift whereby diseases are increasingly identified according to their cause rather than their symptoms by making similar queries for other well-known diseases. Yet, here we must note that Google Ngram raises more question than it answers. To illustrate the benefits, limitations, and hazards of Google Ngram further, we will delve into the contentious and vogue issues of identity, labeling, and political correctness.
English
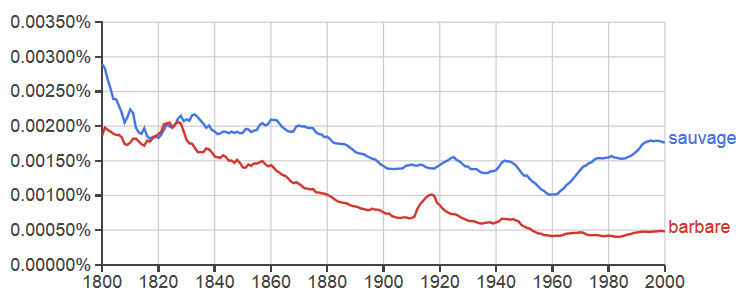
French
Upon seeing the types of data that Google Ngram Viewer can visualize, many historians will probably begin by searching for new or old words related to their topics of study, for example, juxtaposing “Native American” with “American Indian” or putting “Moslem” and “Muslim” side by side. Such searches can result in some surprising indications that encourage further inquiry. The two plots above show the use of the word “savage” and “barbarous” diachronically, with English being on the left and the French translations “sauvage” and “barbare” on the right. While these pairs are good translations for each other, we must acknowledge that they may not be used in identical ways in both languages. They also serve as multiple parts of speech, but Google can account for that (see below). It is also important to note that comparing results from different corpora is statistically problematic because the overall size, the relative quantities of certain document types and distribution of topics in the source materials may differ dramatically. Any statistical biases that result from such differences in the distribution of sources can skew the results. Due to the very massive size of these corpora, the results should nevertheless give us a rough illustration of an underlying trend. In this case, the plot suggests that the word “savage,” which was more commonly mentioned in English than “sauvage” in French ca. 1800, has steadily declined in usage, particularly after 1900. Given the politically incorrect connotations due to its association with various forms of racism and cultural superiority as well as colonialism, this seems intuitive to us. Yet, what is then harder to explain is the parabolic rise and fall of “sauvage” in French, which apparently enjoyed an uptick at the end of the 1950s, precisely as colonialism was on the wane.
These graphs may inspire us to ask further questions; however, they may also be used to illustrate the perils of using n-grams to speculate about sociolinguistic phenomena. For example, if we try to interpret this data in terms of its extra-linguistic meaning, we might say as is commonly and anecdotally observed that the French language has not been impacted by a movement towards political correctness in the same way that English has. While a discussion of these graphs in terms of those questions may make fun and interesting table conversation at Franco-American get-togethers in New York and Paris alike, this is an example of reading something into Google’s data that it simply is not equipped to tell us (just search for even less politically correct words in Ngram and you’ll see data that further proves our point). The message to historians seeking to utilize n-grams is simply that as in all studies of history, unsystematic evaluation of evidence and lack of consideration of contexts will lead to mistakes. The comparative study of political correctness would certainly be a fascinating one, but Google Ngram will not be able to do all the work. Yes, you will still have to read books. Fortunately, Google has digitized many of them!
All of this being said, it is also helpful to remember that Google Ngram utilizes a linguistic corpus organized according to the standards of modern computational linguistics, which is to say that for historians to maximize the utility of n-grams, they will benefit from acquaintance with the ways in which linguists put them to use. Learning what the data represents and how it is intended to be used will both enable researchers to ask more precise question and extract more meaning from their searches.
A Linguist’s Example
Just as digitization tremendously impacts historiography, the horizon of linguistics research has shifted considerably due to the massive increase in availability of language use data in the past several decades. This rise in availability has been accompanied by advances in quantitative methods that permit the statistical patterns in records of human language to be investigated with unprecedented empirical rigor. Linguists now use corpus data to explore questions about language use ranging from raw lexical or phrasal occurrence frequency to patterns in syntax, word meaning, pragmatic interpretations and discourse structure.
These tools are of course not without limitations. Large pools of linguistic data are difficult to organize, and the types of testable hypotheses are tightly constrained by the level of annotation that accompanies the raw data. In this context, annotation can be as simple as tagging each string with its part-of-speech (POS)—a technique known as automatic probabilistic tagging, or it can be as complex as encoding texts into abstract tokens and embedding them in formal representations of discourse structure. As an example, The Penn Tree Bank, the first widely used annotated corpus, offers basic syntactic and semantic information about its constituent sentences. There are also newer specialized corpora such as The Proposition Bank, which is annotated with the semantic role of verbs, allowing for the automated distinction of agent/patient status that would otherwise be conflated by POS alone.
Part of what makes the Google Ngram Viewer so useful for linguists is the same benefit offered to historians, which is that unlike most of the annotated corpora currently available, it offers the option for exploring diachronic questions. The organization of language use data by year opens a category of inquiry about language change that was previously much more speculative. Before Google Ngrams, there were a handful of comparatively small and temporally limited corpora such as the The Diachronic Corpus of Present-Day Spoken English and the Corpus of Contemporary American English (COCA). It should be noted that Google’s corpus, while much larger than these, lacks their breadth of unique tokens due to its hard lower threshold on occurrence; it only includes results that occur at least forty times. This leaves precise questions about the origins of novel words or phrases unanswerable, and it prohibits any type of inquiry about rare constructions or very low-frequency words. Nonetheless, the sheer volume and temporal range of the corpus offers unique advantages for certain types of research.
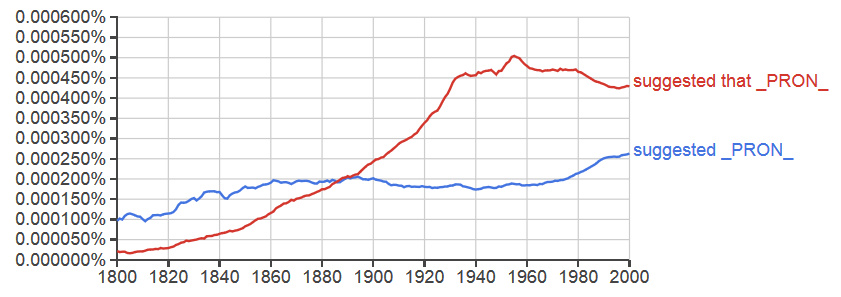
As discussed above, historians might find Ngram useful for exploring the history of certain concepts or identifying historical fluctuations in the importance of topics, but what types of questions would a linguist ask? One typical question about language use that might be asked with Google n-grams regards the historical shift in English complementizer drop patterns. The examples below illustrate how the complementizer “that” may be dropped in many English constructions.
1. Chris knew (that) he would relent on his promise.
2. Kellen thought (that) they wouldn’t mind watching him eat his dinner.
Exploring this issue will require more specialized searches than those conducted above. Fortunately, Google Ngram Viewer allows us to look at the relative frequency of these two possible constructions across nearly two centuries of language use data. The plot below shows the result of this comparison for a particular verb (suggest) that may take a complementizer phrase as an argument.
This change and crossover between the two plots shows us that the typical syntactic pattern for this particular verb underwent a significant historical shift. Collecting trends of this type across different classes of verbs might offer some insight into the pressures underlying this change more generally. This type of shift may for example correlate with known historical events or the rise and fall of publications aimed at certain social registers.
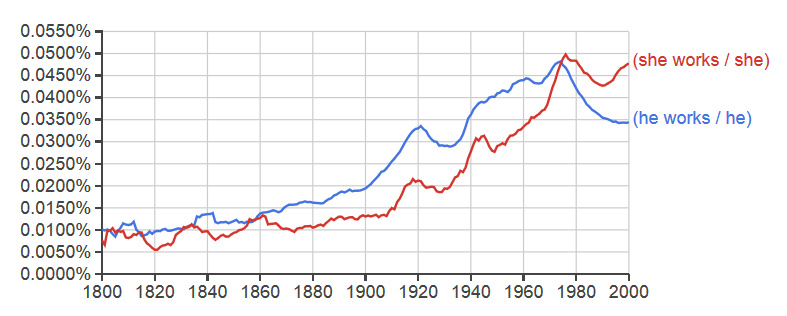
The value of this tool for linguistics researchers is evident, but we would like to stress that making use of basic syntactic information included in Google Ngram’s corpus can benefit social scientists as well. Certain questions couched in language change may offer intriguing insight into changes in cultural trends and standards. The plot below effectively contrasts the proportion of all instances of the pronoun “he” that were followed by the word “works” to the proportion of all instances of the pronoun “she” that were followed by the word “works”. Google Ngram’s division operator allows us to compute these ratios very easily. This measure roughly represents how often, when discussing either a female or male subject, the subject was described as working. Using this more complex n-gram query, we can ask about the relative change in discussion of female work while ignoring the well-known baseline bias for male subjects in published work. We can read the rise in frequency of the feminine phrase as a rise in published discussion of female behaviors as “work” and hence a sort of rough proxy for the increase in socio-cultural normativity of female employment at least within the domains of constituent texts. It is also interesting to note the visible trough in frequency for both bigrams that chronologically coincides with the Great Depression.
While Google n-grams may lack the type of granularity necessary for detailed network-level analysis and fine-grained modeling of language change—and one must resist the temptation of presuming strong causal links where there is only correlation, these examples illustrate the breadth of inquiry that is possible. The sheer size and availability of this tool make it a potentially indispensable resource for research in any field where the use of language might reflect broader aspects of human behavior, such as in psychology, linguistics, history, or anthropology.
The Need for Digitization
In many ways, Google Ngram Viewer further substantiates what has increasingly been argued within the social sciences and humanities since the linguistic turn. Conceptual categories are not stable, and n-grams not only support this claim but also offer ways of studying even the most subtle changes in word use and conceptual nuance through mark-ups that allow researchers to control for the frequency of words in different parts of speech. Yet, it also reveals some disconcerting realities among various fields of study from anthropology to linguistics that have long railed against the reification of Eurocentrism and the universality of the “Western experience.” The Google Books corpus is formed out of the holdings of American libraries and limited by the constraints of current OCR technology (which is for the most part only widely available for European languages). Historians of the Ottoman Empire will find this tool considerably less useful than those who study US or Mexican history, and those who want to make comparative studies will be forced to remain within this Western context.
However, if we assume that the Google Ngram Viewer is not the first and last of its kind, this tool portends an exciting future of corpus-based analysis. As OCR technologies improve to encompass handwritten texts to counteract the biases of a solely print-based representation of linguistic change, the conclusions we can make will grow stronger. This development further emphasizes the utility of digitization projects, and we wish to stress that in regions of the world such as the Middle East where market forces may not push the development of sophisticated OCR, public or private funding for digitization and the expansion of text-recognition will be critical to securing the place of important historical languages such as Arabic or Ottoman Turkish within the growing corpus of human linguistic data.
Chris Gratien is a doctoral candidate in the Department of History at Georgetown University researching the history of disease and ecology in the Ottoman Empire.
Daniel Pontillo is a doctoral student in the Department of Brain and Cognitive Sciences at University of Rochester.
11 January 2014
Cite this: Chris Gratien and Daniel Pontillo, “Google Ngram: an Introduction for Historians,” HAZİNE, 11 January 2014, https://hazine.info/2014/01/11/google-ngram-for-historians/
(Editors’ Note: This is the first of a series of essays that explore different methods and techniques for conducting research and that delve deeper into the histories and ethics of the archives themselves.)
How Digitization has Transformed Manuscript Research: New Methods for Early Modern Islamic Intellectual History
Scholars often treat manuscript libraries only as repositories of unpublished primary sources. We show up at a library, request a manuscript or two, and leave shortly thereafter with a digital or paper copy in hand or we sit at a desk for hours each day, transcribing a manuscript word by word. In most traditional manuscript libraries, this method made sense. Librarians might only pull manuscripts once a day, or even once a week, bringing only a couple of manuscripts at a time. In such conditions, the most efficient course of action is to peruse a library’s catalog, request a few key manuscripts, and read them closely.
Today, however, the mass digitization of manuscripts is blurring the long held boundaries between manuscript libraries and archives and altering the act of research in the process. Scholars often view the changes that digitization entails in a negative light as the physical document is increasingly removed from the hands of the researcher. Here, though, I would like to take a different approach and explore the true possibilities provided by digitization as scholars are able to ask new questions, discover unknown texts, and gain a different understanding of intellectual life in the early modern Islamic world in particular. My belief is that a fundamental shift has occurred now that researchers can view twenty, fifty, or even one hundred manuscripts a day rather than two to three. In what follows, I examine some of the techniques we can use and the insights we can gain when given the opportunity to look at thousands of manuscripts during a research period. Others, of course, have written about the new possibilities for historical scholarship offered by the digitization of archival material, often focusing on the chance for group projects by geographically dispersed researchers. Research with digital manuscripts, though, is still largely an individual affair that requires spending many a long hour laboring away in a dimly lit library, one’s face illuminated only by the glow of a computer monitor. The conclusions below might seem obvious to those researchers already at work in digitized manuscript libraries, but I think it is worth discussing openly the impact of these technologies on the way we research. I hope that my remarks will not only open a discussion among researchers but also inform librarians and archivists as they continue to digitize their collections.
Bookcase by Manolo Valdes
Medieval Precedents and Early Modern Challenges
Our current model of manuscript research is largely the result of the preoccupation of earlier generations of scholars with the medieval Islamic period (c. 800-1200). Until recently, scholars saw this period as an ideal golden age, a time when Islamic thought reached its intellectual climax in all fields. The number of surviving manuscripts was relatively small and those texts that had survived are often only found in renditions from the early modern period (1400-1800). For scholars who studied the medieval period with a “golden-age” mindset, the exercise at hand was to take the few remaining copies of a medieval text and prepare a critical edition in order to rid the text of the corrupting accretions of the ensuing centuries. The desired result was an ur-text in the form of a printed book, reflecting the original intentions of the properly ascribed author that scholars could then use for further analysis. We bear the legacy of this model today whether we use the fruits of these scholars’ labor in research libraries or continue to create critical editions or catalogs ourselves.
When we attempt to study the relatively neglected early modern period (1400-1800) a new set of challenges emerges. The quantity of material overwhelms scholars. There is simply more: more authors, more manuscripts, more copyists, more readers, more marginal notes. Librarians estimate that two to three million Arabic-script manuscripts currently exist in the world, the vast majority copied in the seventeenth to nineteenth centuries, today stowed away in public or private collections. On top of this, many of the authors and the titles are largely unknown to most scholars. Those texts and authors, like Evliya Çelebi or Mustafa Ali, that are traditionally well-known to scholars of the Ottoman Empire only comprise a tiny sliver of this vast corpus of materials. In reality, I would estimate, albeit unscientifically, that we only know of 10-15% of the works and authors of the early modern period, and even these we often know superficially. What little secondary literature that exists can likewise mislead us as to which treatises and authors were actually popular and widely read in the period. It is my personal belief that this relative surfeit of material is due to a gradual expansion of manuscript production and a transformation in reading practices although such claims are relatively under-researched.
Using a Library as an Archive
By changing the manuscript library into an archive, digitization provides us one set of tools to tackle this vast corpus of material and to explore this altered world of early modern readership. To explain what I mean by this phrase let me briefly generalize about the traditional manner of working in manuscript libraries (although I readily recognize that the line separating manuscript libraries and archives is rather artificial). In a traditional manuscript library, you are limited to requesting only a few volumes a day. Often you are allowed only to look at one volume at a time. Since it is tedious to request repeatedly the same manuscript, which might take a few days to arrive, you take careful notes on the manuscript before returning it. The process as a whole takes quite a bit of time and so you limit yourself to those manuscripts that are directly relevant to the research project, already listed in the catalog, rather than discovering the plethora of new material. A digitized library, on the other hand, allows one to view numerous manuscripts, each copy connected to another author or work, and therefore to jump from one to another within seconds. In this sense, the manuscript library becomes a sort of archive as researchers can quickly begin to dredge numerous unknown authors and works from the depths of the library in the same way that researchers working with documents can slowly piece them together to create a larger picture.
The key to such research is a good electronic catalog that keeps texts organized by their original volume. Most works written in the Islamic world before the twentieth century, save extremely long ones, were not individual volumes or codices. Instead, they were grouped together into miscellanies called mecmua (tr.)/majmu‘as (ar.). Even early printed works from the nineteenth century often follow this format. The main value of a mecmua is that it is a collection of texts, meaning that each text often has some sort of association with the other. Mecmuas are compiled through different means. Sometimes a scribe would copy them as a series. Other times they exist as one person’s personal notes, with additions by later readers. Alternatively, a later reader can take a number of unbound works and bind them into a single volume. On rare occasions, the collected texts were simply randomly assembled. These mecmuas can be the collected essays of one specific author or a collection on a theme, such as one particular legal question, or they can be a group of similarly minded texts and authors. By looking at mecmuas, even simply through a catalog that lists them together, you can start to understand which texts were read with one another, that is, you begin to discover the intertextuality of a scholarly world and thus enter the minds of early modern people. In this fashion, you can begin to break out of the straightjacket of well-known texts and discover those thousands of (relatively) unknown authors.
My personal method, which is only one of many possibilities, is to start my research with the names of a few authors or treatises. Even a few keywords will do. Let us use dreams as an example. You type “rüya” or “rü’ya” or “ruya” into the computer catalog and fifty or so results are returned. To gain more results, you type in “rü’y” or “rüy.” You start examining the search results, one by one, taking notes of authors and titles. You look at the works in mecmuas, paying attention to those other texts compiled alongside. Often the process brings up other texts on dreams that do not necessarily have the word “dream” in the title. This then gives you more titles and author names to search. You can then take each of these authors and search them by name. Some are minor characters with only a few other treatises, others are famous authors with hundreds of treatises, yet others are false attributions. You can then look at the other treatises by each author to see if they also deal with dreams and to get a sense of the other issues that were important to them. Slowly you develop a sense of what genres dealt with dreams and visions and the important personalities that are commonly cited. You find that there are dream interpretation manuals, treatises on the veracity of dreams, and a whole line of debate on visions of the Prophet Muhammad. You can gauge which are medieval copies of old treatises, new copies of medieval treatises, or relatively new works made in the early modern period.
Even works that are titled incorrectly or vaguely, like “a treatise on dreams,” can be valuable. The false attribution is helpful in and of itself as it is often the result of a mental connection made by a reader centuries ago, picked up by an unsuspecting cataloger. Vague titles that refer to a work generically or topically rather than by its actual name can often point to a more well-known treatise whose title never contained the word “dream.” Alternatively, it could be a piece that circulated anonymously and that readers or scribes attributed to various famous figures. After surveying the texts in this fashion, you can start to ascertain the correct titles and authors, often simply overlooked by catalogers, or by comparing the texts to other versions.
Once you find an author of interest, start by listing all of his works and every copy of each of his works. Then as you start to scan through them, look again at the mecmua in which each text is located and take note of recurrent treatises or those that pique your interest. When you look at the treatise, make sure to look at the colophon and note the copy date and the copyist as well as any marginal notes and the notes’ authors. If the author or a later reader has written a table of contents, see what they emphasize and how they organize the material. Then you look at the mecmua as a whole, attempting to see if it was copied by the same scribe or sewn together at a later date. (If the same scribe wrote a mecmua then you can use the neighboring works in the mecmua that possess copy dates to estimate the copy date of other treatises.) If the digital copy is of sufficient quality, examine the paper type, the binding, and the sewing to gauge the overall value of the book—whether it was an expensive or cheap volume. Look at ownership statements and library endowment stamps and compare them to the reference lists. Each offers a valuable piece of information. Then you can search the names of the copyist and owners, sometimes coming up with their own works or other copies. Each time you find an intriguing treatise or author, follow that lead to see what associations you can build up. With authors who possess relatively modest oeuvres, with perhaps five to fifteen in a library, you can complete this process fairly quickly. Authors with hundreds of copies of their works will need days of scrutiny.
In the process of all this surveying you not only gain a sense of a field of literature and its authors, you also come across a great deal of minor but important minutiae hidden away in the pages of the manuscripts. You encounter favorite poems, rants, announcements of births, descriptions of historical events, legal rulings, medicinal recipes, lists of books and more. You can use these seemingly trivial asides to find new figures or to contextualize a text, assuming you can pin this material to the correct period, as any later reader could have added these bits. Catalogers often skip the personal notes and thoughts of readers and copyists since they do not necessarily have a discrete author or title, though they are often some of the most valuable sections of manuscripts. You also find many cataloging mistakes, whole treatises skipped over in haste or simply ignored because they did not appear to be worthwhile and “complete” texts. Often the most obscurely or generically labeled treatise is the most interesting, something that a cataloger overlooked because it was too hard to properly identify and describe.
Digitization as Opportunity
In short, the method I outlined above starts with a few figures and slowly establishes a network of people, places, and titles. Each new discovery becomes a new node in this world of early modern thought that can lead us to even more authors and titles. In some sense, you are creating a personal catalog or map, but rather than organizing material by alphabetical author or generalized topic, this catalog connects the writers, readers, and books of a period. Once you achieve a grasp of a period as a whole, you can then focus on particular works and read them closely. The intention of such research is never to replace the close examination of a text but rather to chart the relatively unknown intellectual world of early modern Islamic societies so you can accurately choose the most relevant texts to read.
Of course, you can do such work with the physical manuscripts, but digitization makes it practical and efficient. When you can look at twenty, fifty, one hundred manuscripts in the same day, side by side, following whatever lead you might come across, research that might have taken five years can be done in a year. Moreover, a good digital catalog allows you to search across multiple manuscripts for pieces of titles or author names in a keystroke rather than flipping through the indices of multiple volumes.
There are downsides to the digitization of manuscripts. Scholars often lament, and rightfully so, the inability to interact tactilely with a physical copy, to sense its dimensions and quality with more than just a doubly distant pair of eyes. Employees digitizing the manuscripts often forget to photograph the bindings and covers. The best manuscript libraries allow researchers to access the originals if necessary, though many do not. Some libraries combine the worst of both worlds, forcing researchers to wait for days to read a few digital copies at a time as well as refusing them the privilege of viewing the actual manuscript. Finally, a library is only as good as its catalog. If catalogs, whether paper or electronic, do not accurately list basic information or do not display the mecmua as a whole, and instead treat every treatise as an independent work, then research becomes even more difficult and inefficient. Finally, the true benefits of working with digital manuscripts only become apparent when you have tens of thousands of manuscripts to browse. Only then can you easily track down all the different copies of a treatise and see, within a few seconds, what else the author may have written. For the moment, I am of the opinion that there is only one possible location for such research—Süleymaniye Library in Istanbul—although its catalog leaves much to be desired. The other major libraries, like Dar al-Kutub in Cairo, are a long way off from complete digitization.
Despite these frustrations, I still think that the digitization of manuscripts provides unique solutions to the problem of studying early modern intellectual history in particular. We can discover many of the poorly known authors and treatises of a period (that is, poorly known to us) in an efficient manner without having to rely on sheer chance. In this sense, it might have less to offer to those researchers studying medieval Islamic societies as the vast majority of mecmuas are from the early modern period. Perhaps most importantly of all, it allows us to address that most elusive question of readership and reception. Only when we can quickly go through twenty or thirty manuscripts in a few hours, looking at comments, ownership marks and more can you start making sense of the circulation and reception of these texts. We can pay attention to the short, sundry pamphlet-like literature that was so prevalent in the early modern period, rather than focus on one grand, though seldom-read text. Digitization allows us to access the expanded world of early modern readership. No longer chained to one ur-text, we can compare the many variants and changes of a text. By paying attention to this material world of manuscript reception, we might be able to find a new path between seeing these texts either purely as repositories of facts or as representations. In this sense, although digitization has distanced researchers from the material text itself, it has simultaneously refocused our attention on the manuscript as a medium worthy of study and respect.
(Many thanks to the friends and colleagues who commented on earlier draft. Readers’ comments and thoughts are welcome and encouraged.)